Seskupování a filtrování dat

Seskupování a filtrování dat
Chtěli jste někdy větší rozlišení dat nebo objektů v Grasshopperu? Chtěli jste například někdy vybrat pouze objekty v modelu, na které je aplikován určitý materiál (např. sklo)? Nebo jste možná chtěli odstranit všechny povrchy v modelu, které se nacházejí v určité vrstvě a jejichž plocha je menší než určitá hodnota. Dokázali byste to (snadno)?
Grasshopper 1 pro Rhino 8 obsahuje nové komponenty, které vám pomohou efektivněji spravovat data.
Abychom vysvětlili, jak tyto nové komponenty fungují, je nejlepší začít na jednoduchém příkladu. Stáhnete si soubor Massing model, ve ketrém jsou objekty (tzv. BREP - Boundary REPresentation) představující vnější plášť budov a také plochy, které slouží jako podlaží. Tyto objekty byly umístěny do různých vrstev a byly jim přiřazeny různé barvy podle typu využití (kancelářské, obytné, prodejní atd.).
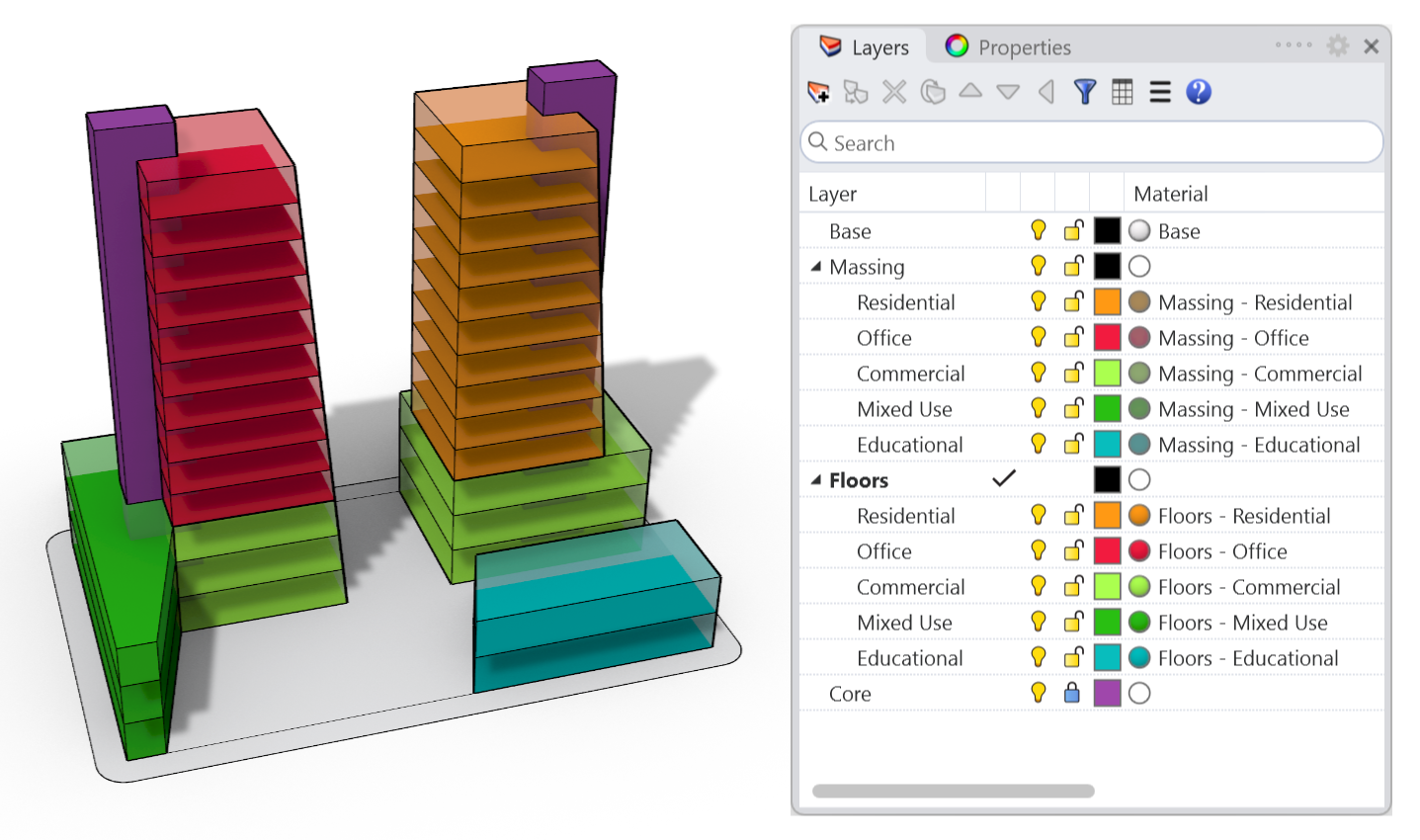
K většině objektů jsou také připojena určitá metadata v podobě uživatelských textových položek.
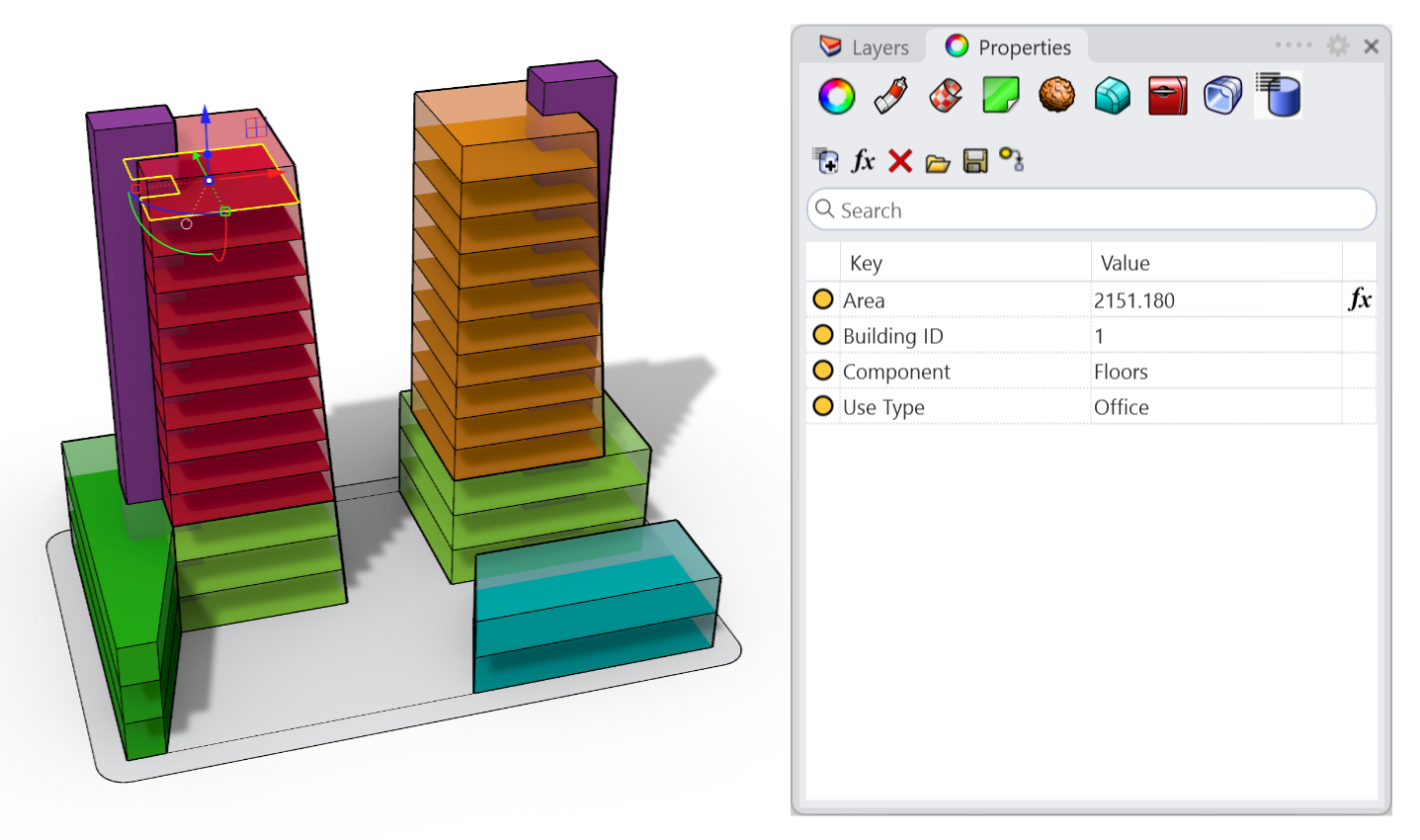
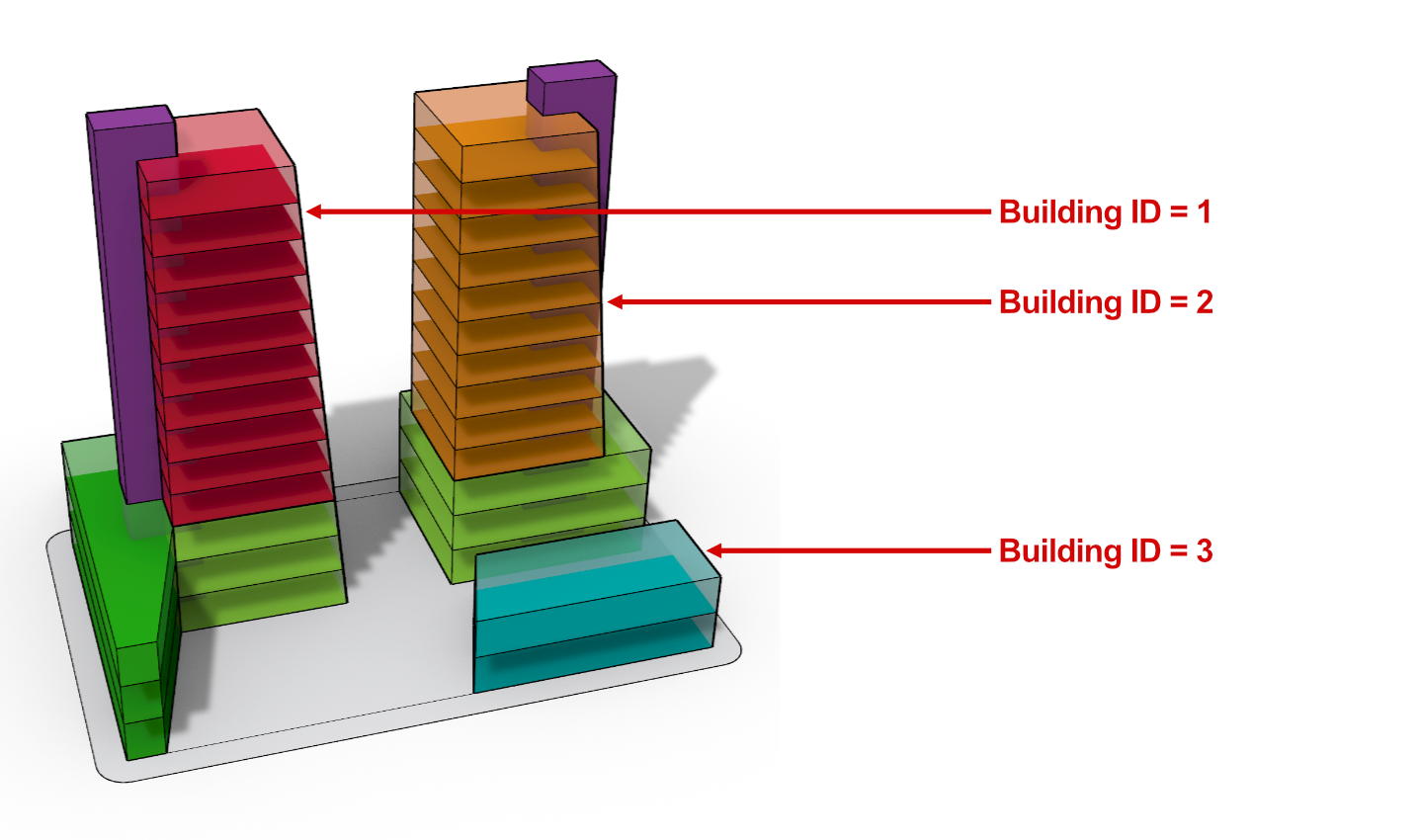
Začněme tento návod tím, že zjistíme celkovou podlahovou plochu každé budovy v našem hmotovém modelu. V našem modelu máme tři hmoty budov. Každá z podlahových desek má přiřazeno identifikační číslo budovy (ID) jako uživatelský textový údaj.
Seskupování obsahu
Začněme tím, že otevřeme editor Grasshopperu a klikneme na File > New document, čímž zahájíme novou definici.
Abychom zjistili celkovou podlahovou plochu každé budovy, musíme nejprve do definice Grasshopperu vložit odkaz na všechna podlaží v našem modelu Rhino.
Tento návod je celý o filtrování dat. Protože jsme náš model pečlivě uspořádali podle vrstev, můžeme podlaží filtrovat pomocí vstupu Layer komponenty Query Model Objects (najdeme ji v záložce Rhino v podkategorii Object). Použitím zástupného znaku "*" za slovem Floors se vyberou všechny objekty v podvrstvách Floors (podlahy).
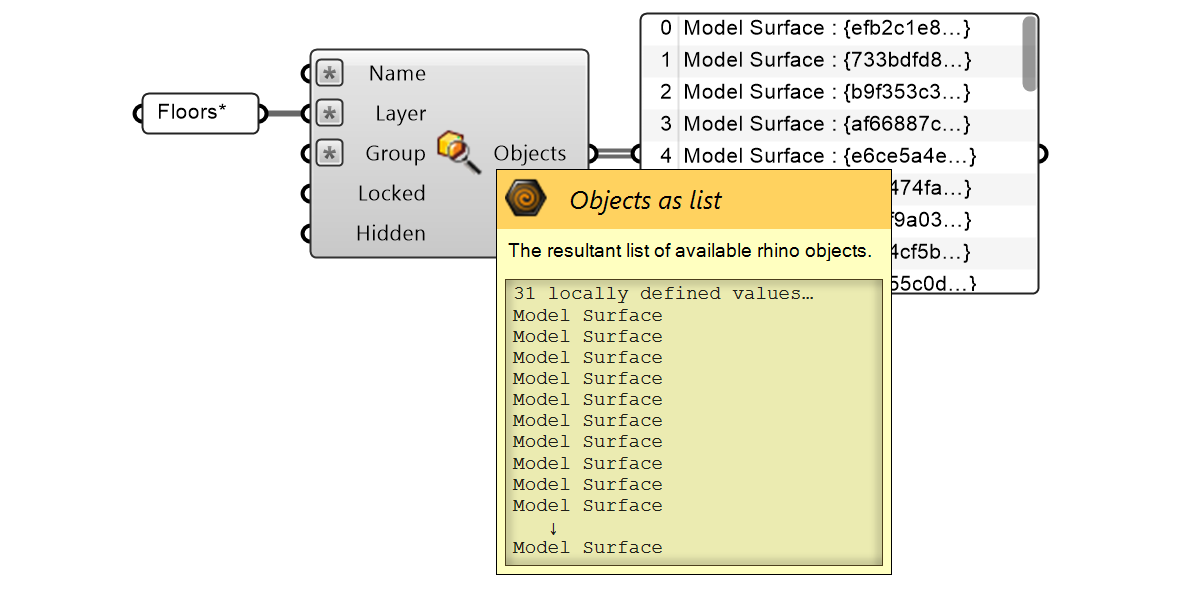
Po najetí myší na výstupní parametr Objects zjistíme, že zde máme 31 ploch, které představují jednotlivé podlahové desky v našem modelu.
Dále musíme každou z těchto podlahových desek seskupit pomocí ID budovy jako kritéria seskupení. Použijeme komponentu Group Content (nalezneme ji v záložce Rhino v podkategorii Content) a připojíme výstup komponenty Query ke vstupu Content.
Tato komponenta používá vstup Key k určení způsobu seskupení obsahu do různých větví datového stromu. Po kliknutí pravým tlačítkem myši na vstup Key se zobrazí několik možností.
Select Type - v tomto menu můžete vybrat, zda chcete obsah seskupit podle uživatelského textového klíče nebo podle atributu datového typu. V tomto případě chceme objekty seskupit na základě uživatelské textové hodnoty ID budovy, takže musíme z menu vybrat možnost "User text"..
Select Property/Key - v závislosti na výše uvedeném výběru z menu se v ovládacím prvku stromového zobrazení zobrazí seznam dostupných vlastností nebo klíčů, které můžete použít jako kritéria filtrování. Pro tento příklad můžeme vybrat klíč "Building ID".
Při pohledu na výstup Obsah jsou nyní všechna patra rozdělena do různých větví podle identifikačního čísla budovy. Výstup Values vrací seznam všech jedinečných hodnot klíčů, které v obsahu našel. V tomto případě vidíme seznam tří hodnot (1, 2 a 3), které odpovídají jedinečným hodnotám ID, jež byly nalezeny v seznamu obsahu, a také větve datového stromu seskupeného obsahu.

Posledním krokem tohoto procesu je sečtení všech obsahů ploch v jednotlivých větvích našeho datového stromu. Protože jsou nyní všechny naše podlahové plochy rozděleny do různých větví, je poměrně snadné předat výstup komponenty Group content komponentě Area a poté všechny tyto hodnoty sečíst pomocí komponenty Mass addition.

Z výše uvedené definice Grasshoppera můžeme určit, že:
- Bulding 1 = 43 622 sf (čtverečních stop)
- Bulding 2 = 36 626 sf
- Bulding 3 = 5 736 sf
Krása tohoto pracovního postupu spočívá v tom, jak snadno lze měnit kritéria seskupování. Řekněme například, že chcete určit celkovou plochu jednotlivých typů využití (obytné, kancelářské, komerční atd.), a ne pouze celkovou plochu jednotlivých budov. V tomto případě stačí změnit vlastnost Key na "Use Type". Vše ostatní může zůstat stejné.
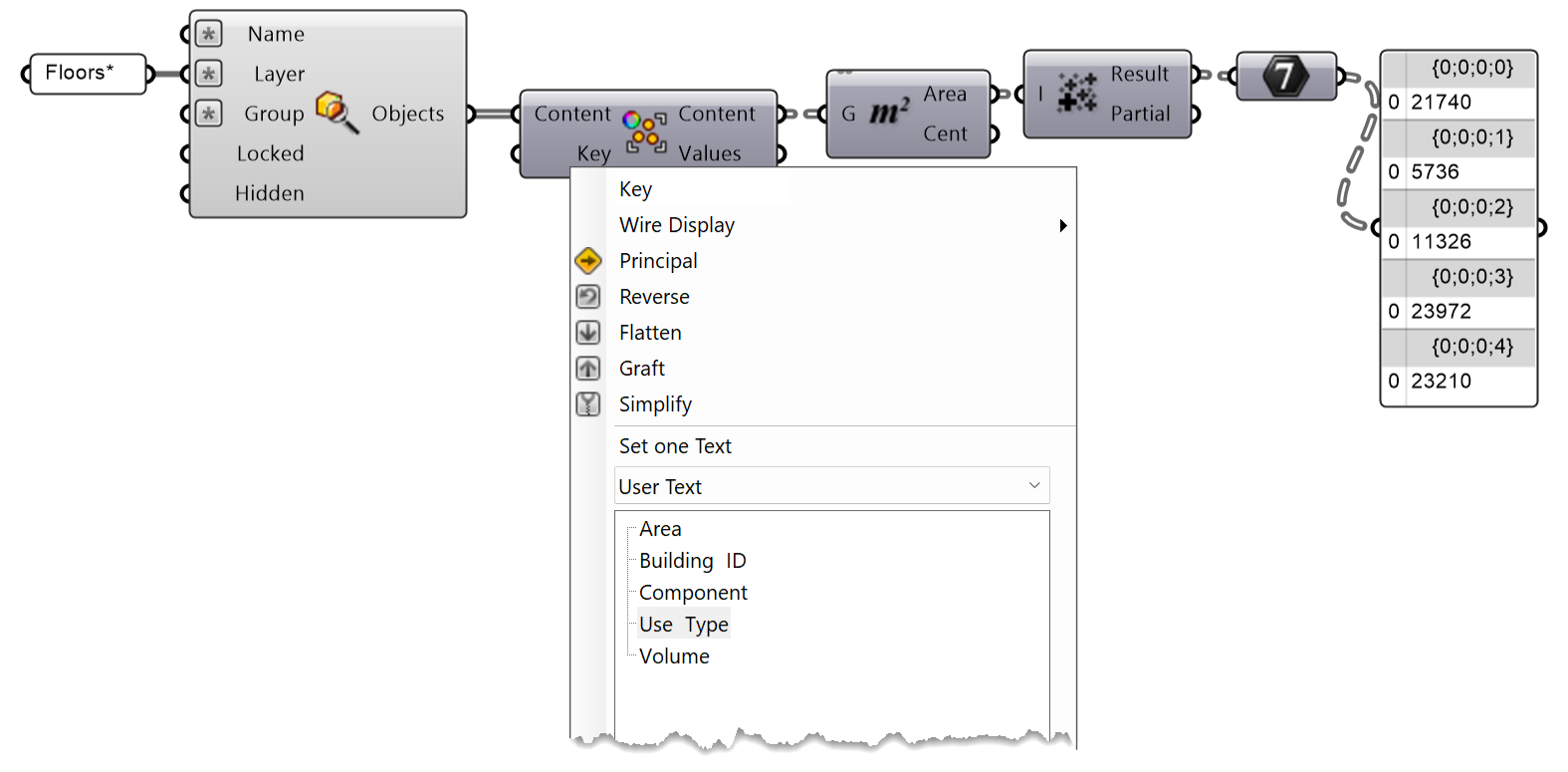
Po přepnutí kritéria seskupení na "Use type" bude celková plocha v součtu následující (sf = čtvereční stopy):
- Commercial = 21,740 sf
- Educational = 5,736 sf
- Mixed Use = 11,326 sf
- Office = 23,972 sf
- Residential = 23,210 sf
Filtrování obsahu
Kromě seskupování můžeme obsah filtrovat také na základě splnění určité podmínky. Podmínka filtrování typicky porovná jednu vlastnost objektu s jinou a vrátí logickou hodnotu (True nebo False). Ptáme se například, zda se x rovná y? Nebo je x větší nebo rovno y? Tato pravidla můžeme také kombinovat do složitějších výrazů pomocí operátorů.
Vezměme tedy náš stávající model a vytvořme řadu filtrů, které budou rozdělovat podlahové desky podle následujících kritérií:
- Use Type musí být typu “Office” A
- Podlahová plocha musí být větší než 2 250 čtverečních stop A
- Podlahová plocha musí být také menší než 2 500 čtverečních stop
Začněme vytvořením nové definice v Grasshopperu. V menu Grasshopperu klikněte na File -> New document. Stejně jako v předchozím příkladu použijeme komponentu Query Model Objects s filtrem Layer nastaveným na "Floors" (Podlahy), abychom do našeho dokumentu Grasshopperu vložili odkaz na všechny podlahové plochy. Výstup by měl obsahovat 31 ploch (Surfaces), které představují jednotlivé podlahové desky v našem modelu.
Dále vytvoříme filtr, který definuje naši první výše uvedenou podmínku - vyfiltruje všechny podlahové desky, jejichž typ užití se rovná typu "Office". V záložce Rhino a v podkategorii Content máme k dispozici řadu různých filtrů, z nichž několik může kontrolovat rovnost. Pro tento tutoriál však začneme tím, že na naše plátno přidáme komponentu Match Text.
Filtr Match Text je velice výkonná a flexibilní komponenta pro porovnávání textu. V tomto filtru chceme projít každou podlahovou desku a získat hodnotu přiřazenou uživatelské textové položce "Use Type. Poté tuto hodnotu porovnáme, zda se shoduje se slovem "Office", a podle toho objekty vyfiltrujeme.
Filtr Match Text má tři režimy, podle kterých může pracovat. Pokud kliknete pravým tlačítkem myši na střed komponenty Match Text, zobrazí se seznam tří režimů:
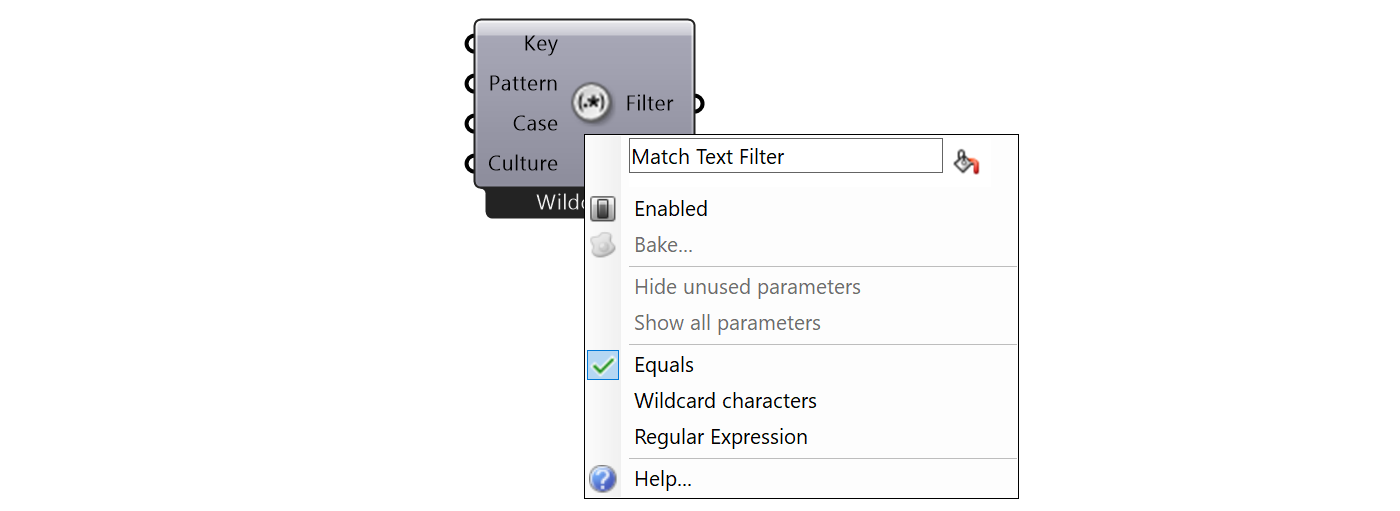
V tomto příkladu nás zajímají pouze textové hodnoty, které se rovnají slovu "Office". Vybereme tedy režim Equals v nabídce pravého tlačítka myši filtru Match Text .
Dále musíme zadat vstup Key, který určí způsob filtrování obsahu. Opět, stejně jako v předchozím příkladu, můžeme kliknout pravým tlačítkem myši na vstup Key a z menu vybrat možnost "User TEXT" a z ovládacího prvku stromového zobrazení vybrat možnost "Use type".
Posledním krokem je definování vstupu Pattern v komponentě Match Text Filter, abychom určili, s jakou hodnotou textu budeme porovnávat. V tomto příkladu chceme zkontrolovat, zda se hodnota Use Type rovná slovu "Office", takže můžeme do vstupu Pattern přidat textový panel s tímto slovem.
Nyní, když jsme vytvořili filtr, musíme na naše plátno přidat komponentu Filter Content, která provede vlastní akci filtrování. Obsah, který chceme filtrovat, je 31 BREP (Boundary Representation), které jsou vráceny z komponentou Query Model Objects. A filtr, který chceme použít, je ten, který jsme právě vytvořili pomocí filtru Match Text.
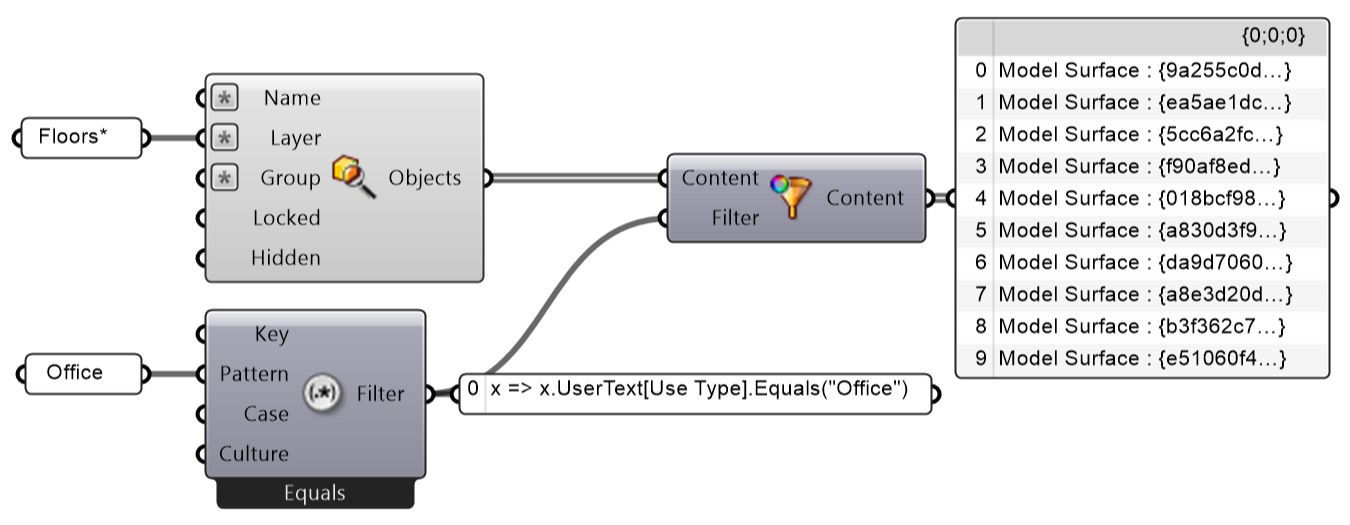
Při pohledu na výstup nyní máme pouze 10 ploch, které vyhovují našim kritériím filtrování (tj. ty podlahové desky, které odpovídají typu kancelářského využití - "Office"). Tím však ještě nejsme zcela u konce. Chtěli jsme také vyfiltrovat podlahové desky na základě toho, které z nich mají plochu větší než 2 250, ale menší než 2 500 čtverečních stop.
Přidáme komponentu filtru Greater Than a umístíme ji pod naši komponentu filtru Match Text. Stejně jako předtím musíme nastavit vstup Key, abychom definovali, jakou hodnotu chceme v tomto filtru porovnávat. V tomto případě chceme nastavit Key tak, aby se díval na hodnotu uživatelského textu Aera. Klikněte tedy pravým tlačítkem myši na vstup Key a v ovládacím prvku stromového zobrazení vyberte možnost "Area".
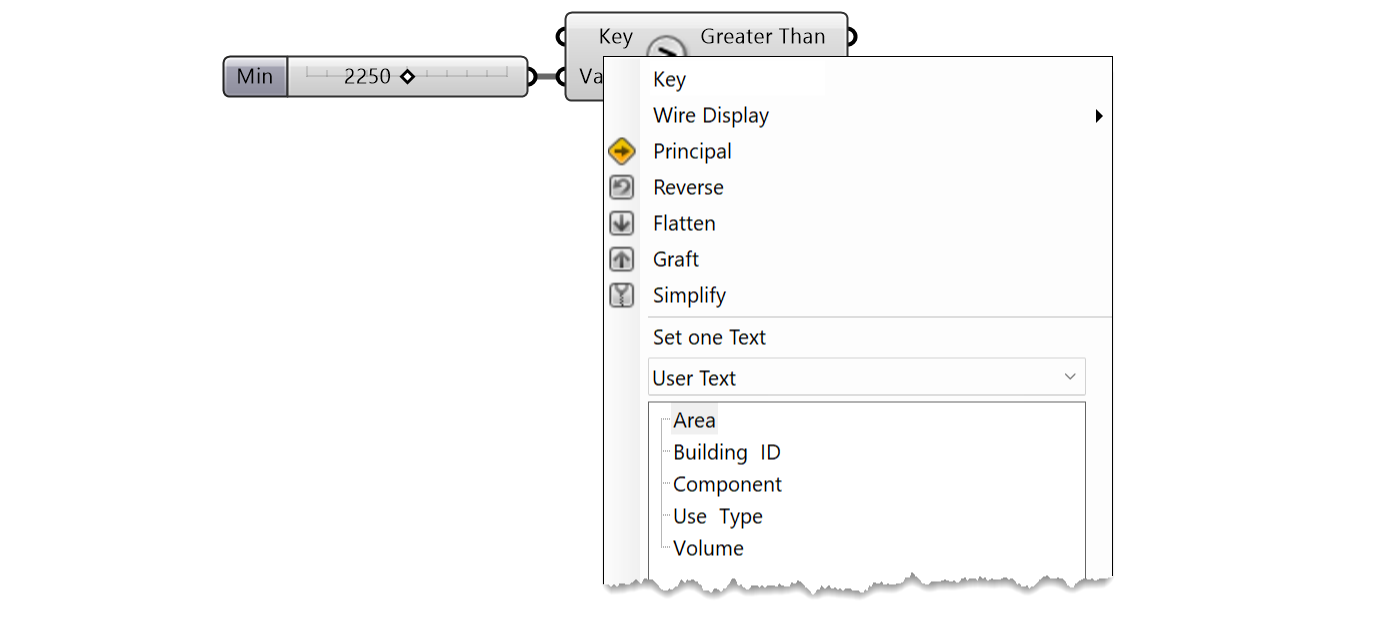
Dále je třeba definovat číselnou hodnotu, se kterou budeme porovnávat naši hodnotu plochy. Přidáme číselný posuvník (nalezneme jej na záložce Params v podkategorii Input) a nastavíme hodnotu 2 250. Minimální a maximální hodnotu tohoto posuvníku můžete nastavit na libovolnou hodnotu, já jsem však zvolil hodnoty 2 000 a 2 500.
Nyní jsme vytvořili filtr, který kontroluje podlahové plochy větší než 2 250 čtverečních stop. Vytvoříme další, který vyhledá podlahové desky, které jsou menší než 2 500 čtverečních stop.
Přidejte komponentu filtru Smaller Than a umístěme jej pod filtr, který jsme právě vytvořili. Nastavte vstupní hodnotu Key na uživatelskou textovou hodnotu Plocha. Vyberte posuvník, který jsme právě vytvořili, a na naše plátno zkopírujte nebo vložte další. Hodnotu tohoto nového posuvníku nastavte na 2 500 a jeho výstup připojte ke vstupu Value komponenty Smaller Than Filter.
Nyní máme v definici tři filtry, které odpovídají kritériím definovaným výše. Musíme je však spojit dohromady, aby všechny tři filtry musely být pravda, aby se obsah správně filtroval. K tomu použijeme komponentu Intersection Filter.
Intersection Filter umožňuje kombinovat více filtrů dohromady a vrátí hodnotu TRUE pouze v případě, že všechny vstupní filtry mají hodnotu TRUE. Se stisknutou klávesou SHIFT připojte výstupy našich tří filtrů na vstup Filters komponenty Intersection Filter.
Nakonec nahraďte filtr Match Text, který je připojen ke vstupu Filter komponenty Filter Content, výstupem Intersection Filter. Vaše definice by měla vypadat jako na obrázku níže.

Všimněte si, že nyní máme pouze 5 BREP, které jsou vráceny z komponenty Filter Content. Jedná se o 5 podlahových ploch, které odpovídají typu využití "Office" a jsou také větší než 2 250, ale menší než 2 500 čtverečních stop.

